Data Loading
In this section we will discuss how to load the data prepared in Data Preparation into the Metascatter tool.
We will explain with the help of the Stanford Dog Breed Classification dataset (CSV download).
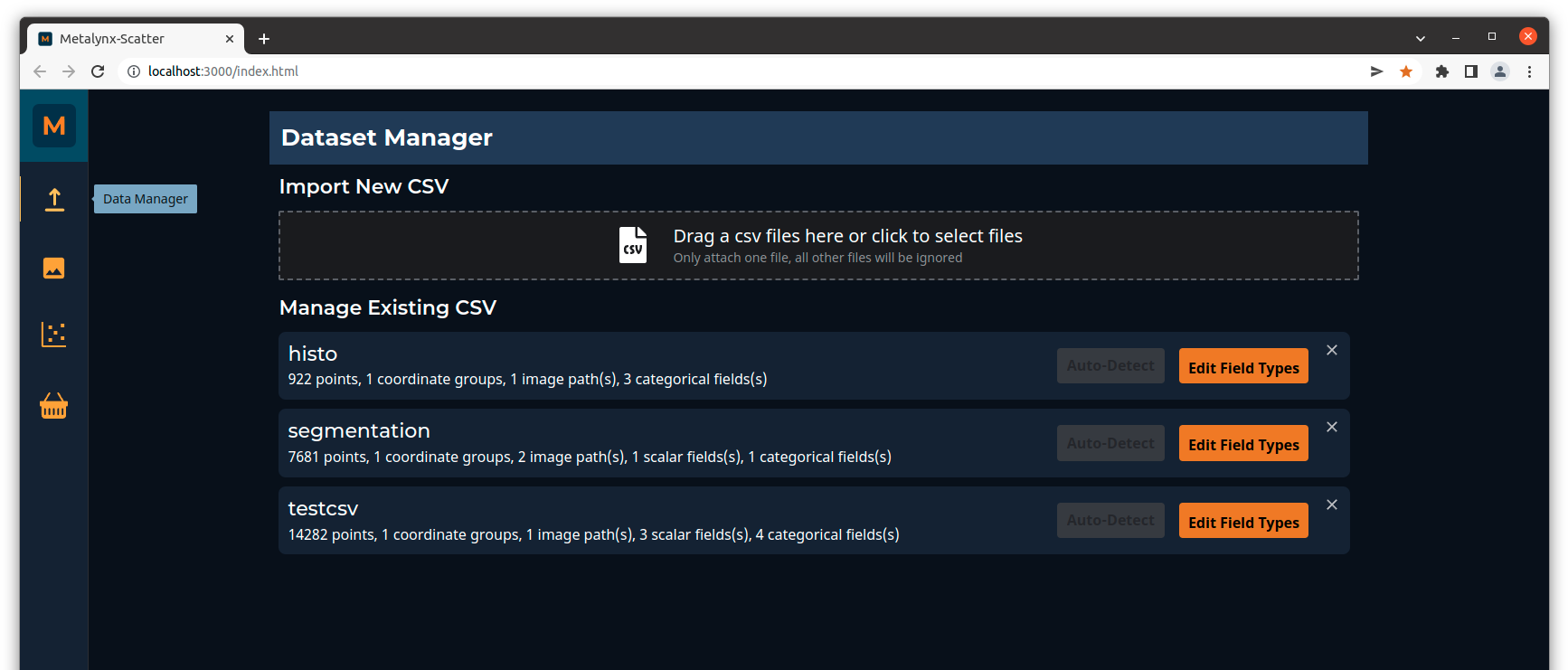
To load a new data file click on the Data Manager tab on the left menu and click on Import New CSV.
Each column in the CSV is mapped to a field in Metascatter and many should automatically be detected. You may have to edit some manually though (for instance, if a field is detected as type 'Unknown'). The field types you can choose from are:
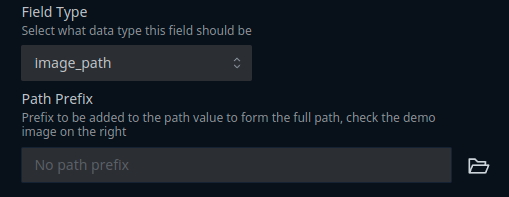
Image_path: should contain paths of each image. If you are using images stored locally, your CSV should use relative paths (absolute paths will take longer to load), and you will need to enter the root to the relative path in the Path Prefix box. You can search for the root folder by clicking on the folder icon next to the path prefix box.
Co-ordinate group: columns with the heading
features0andfeatures1will automatically be detected as co-ordinates of the scatter plot. Don't forget to edit the Manage Coordinates section if you've had to change these or if you have more than one set of co-ordinates!
Categorical: e.g. a label category or source type such as TRAIN/TEST/VAL.
Scalar: for numerical values such as prediction confidence or intersect over union.
Note that you can have several of each field type e.g. multiple image paths for images, bounding boxes or pixel level segmentations. You can view different sets of images in the Image Explorer using the Image path selector menu at the top of the page.
You can also include more that one set of co-ordinates, for instance, if you have feature embeddings from different models or ones extracted from different layers. These can be selected in the Scatter Plot using the Select Projection menu at the top of the page.